Real-World Language-Driven Zero-Shot Object Navigation
Introduction
In an innovative exploration within the realm of Learning-based Computer Vision, our project, Real-World Language-Driven Zero-Shot Navigation, harnesses the synergy between advanced robotics and cutting-edge AI. This project bridges the gap between linguistic commands and autonomous navigation, enabling a Viam Rover equipped with an Intel Realsense Depth D435 camera to locate and navigate towards specific objects based solely on textual descriptions.
The Challenge
The core challenge was developing a system capable of executing commands like "Find a black colored water bottle" in an unknown environment, showcasing the ability to generalize from known concepts to unseen objects through zero-shot object navigation.
Our Solution
We crafted a sophisticated pipeline that integrates the CLIP segmentation model with ImageBind embeddings for multimodal processing of visual, depth, and textual data. This innovative approach allows the rover to autonomously navigate towards and identify objects based on textual prompts.
Technical Highlights
- Integration of CLIP and ImageBind Models for advanced object recognition.
- Utilization of depth sensing for precise object localization and navigation.
- Employment of heatmap analysis to pinpoint the object's location with high accuracy.
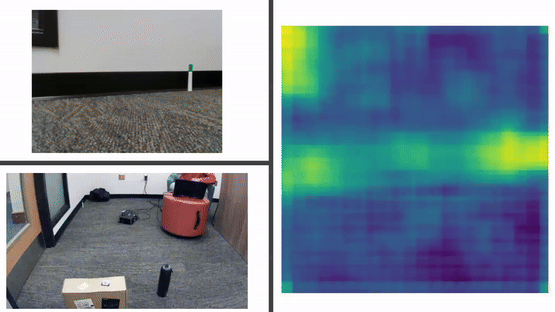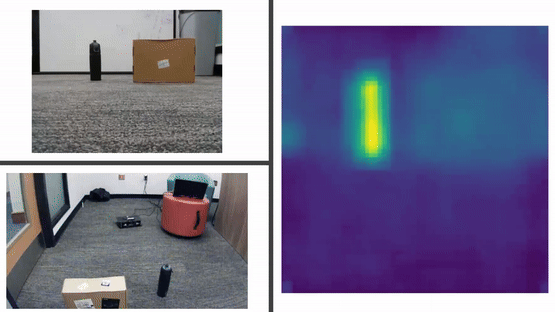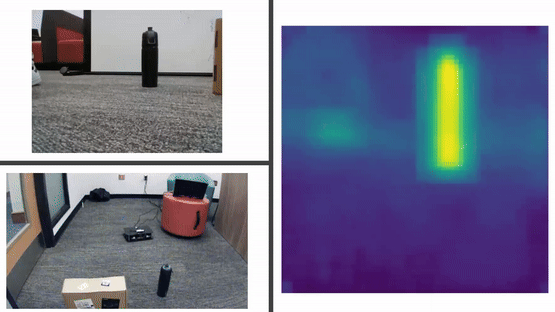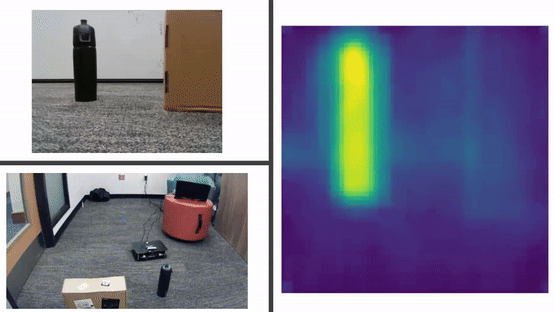
ImageBind Analysis
In our experiments, we leveraged ImageBind embeddings to process data from different modalities, including visual, depth, and textual data, to enable our Viam Rover to navigate towards objects such as a Box, Bag, Bottle, Marker, and Laptop. Our approach tested three combinations of embeddings:
- Text + Colored Image
- Text + Depth Image
- Text + Depth + Colored Image
We found that the Text + Colored Image combination performed exceptionally well, Text + Depth alone was less effective, and Text + Colored Image + Depth achieved success in navigating towards 3 out of 5 objects.
Strengths
- Able to combine vision and depth data for navigation towards unseen objects based on language prompts.
- Depth attention maps lacked accuracy and tended to decrease the performance of image attention maps.
- Observations suggest ImageBind's focus is primarily on audio, image, and text modalities, with less effective performance on depth data.
Impact and Future Directions
This project opens new pathways for robotic applications in diverse fields such as search and rescue and home assistance. Future work will focus on enhancing the integration of multimodal data and exploring advanced segmentation models.